
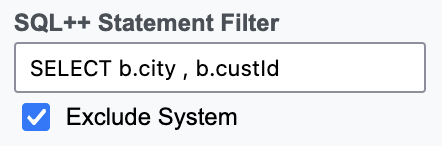

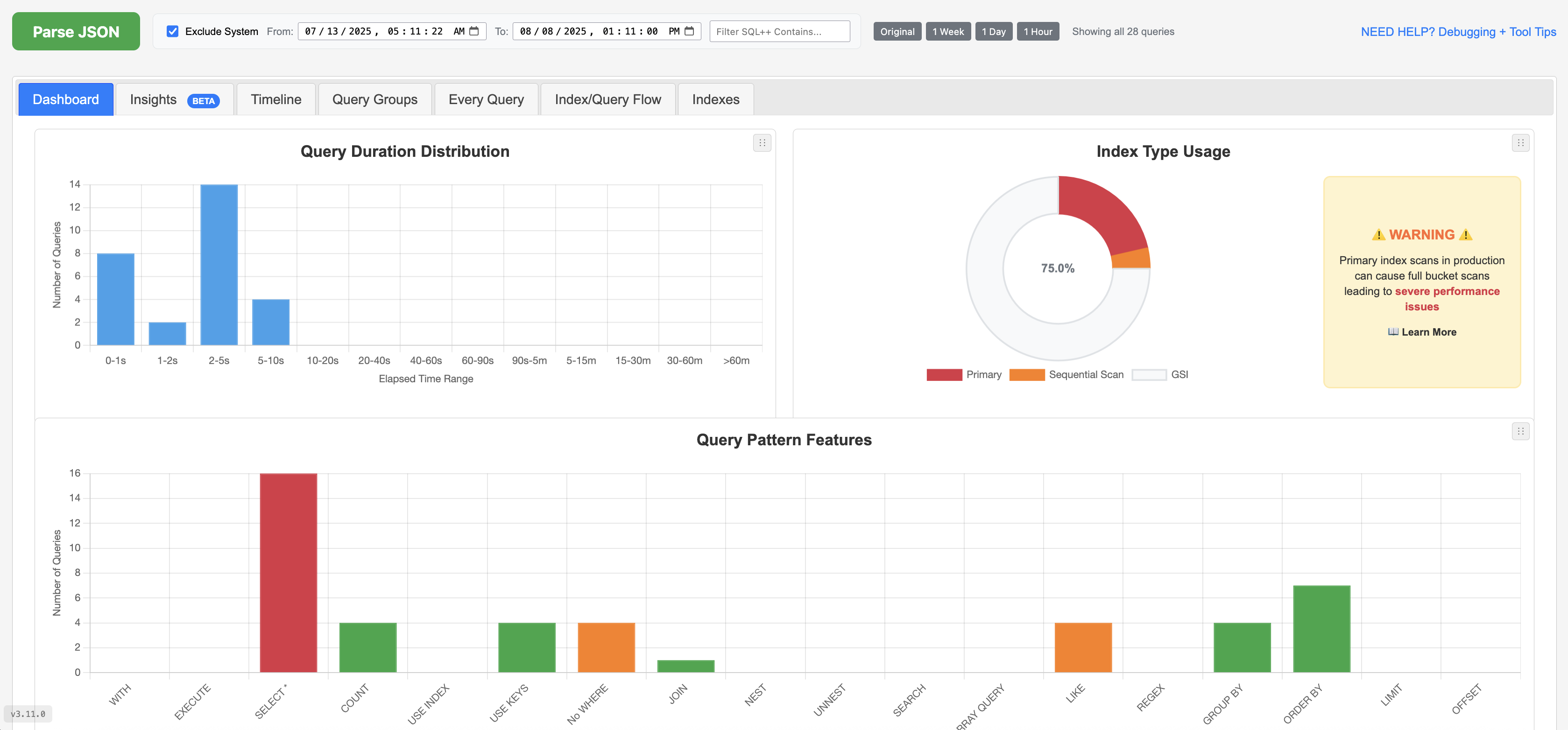
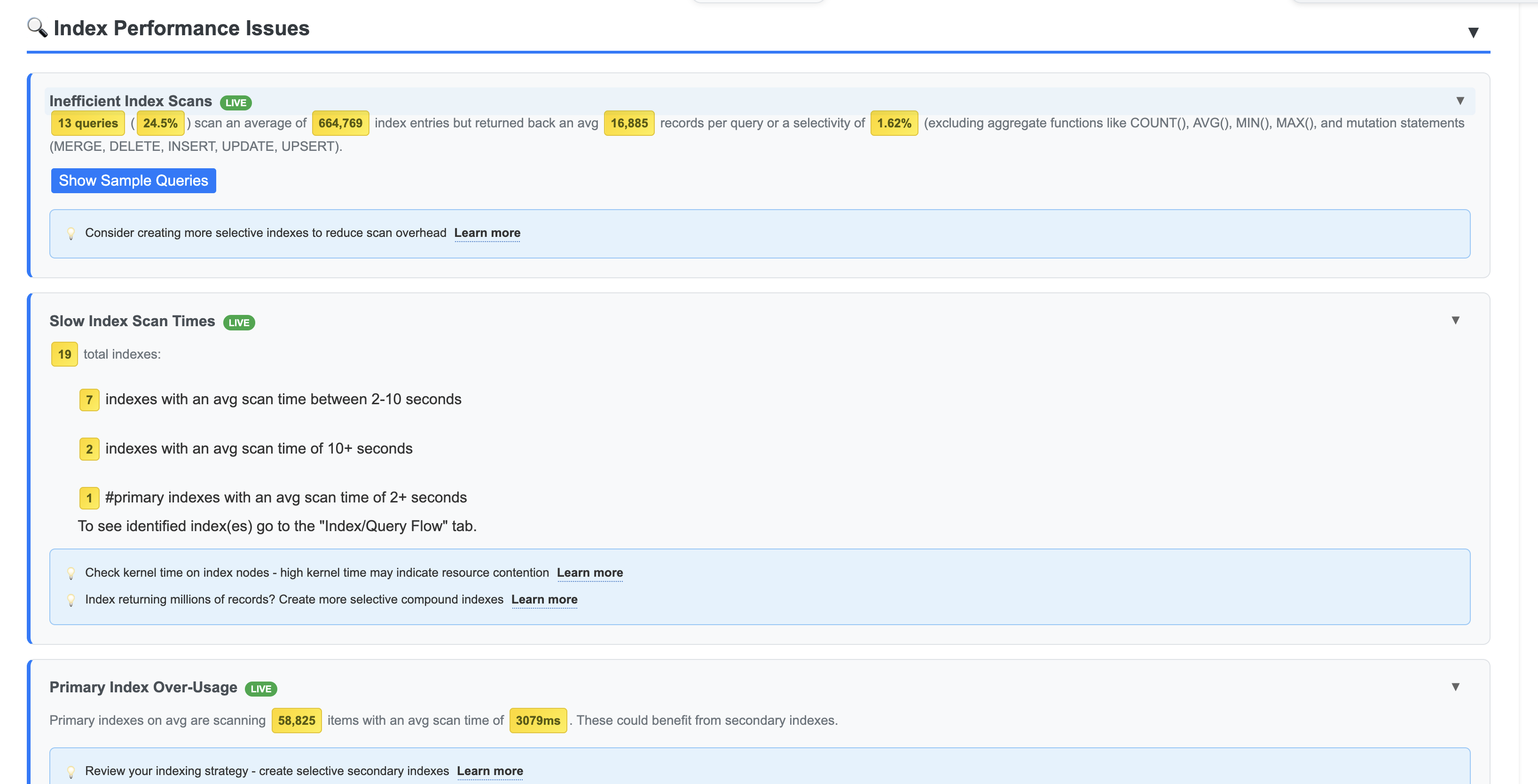
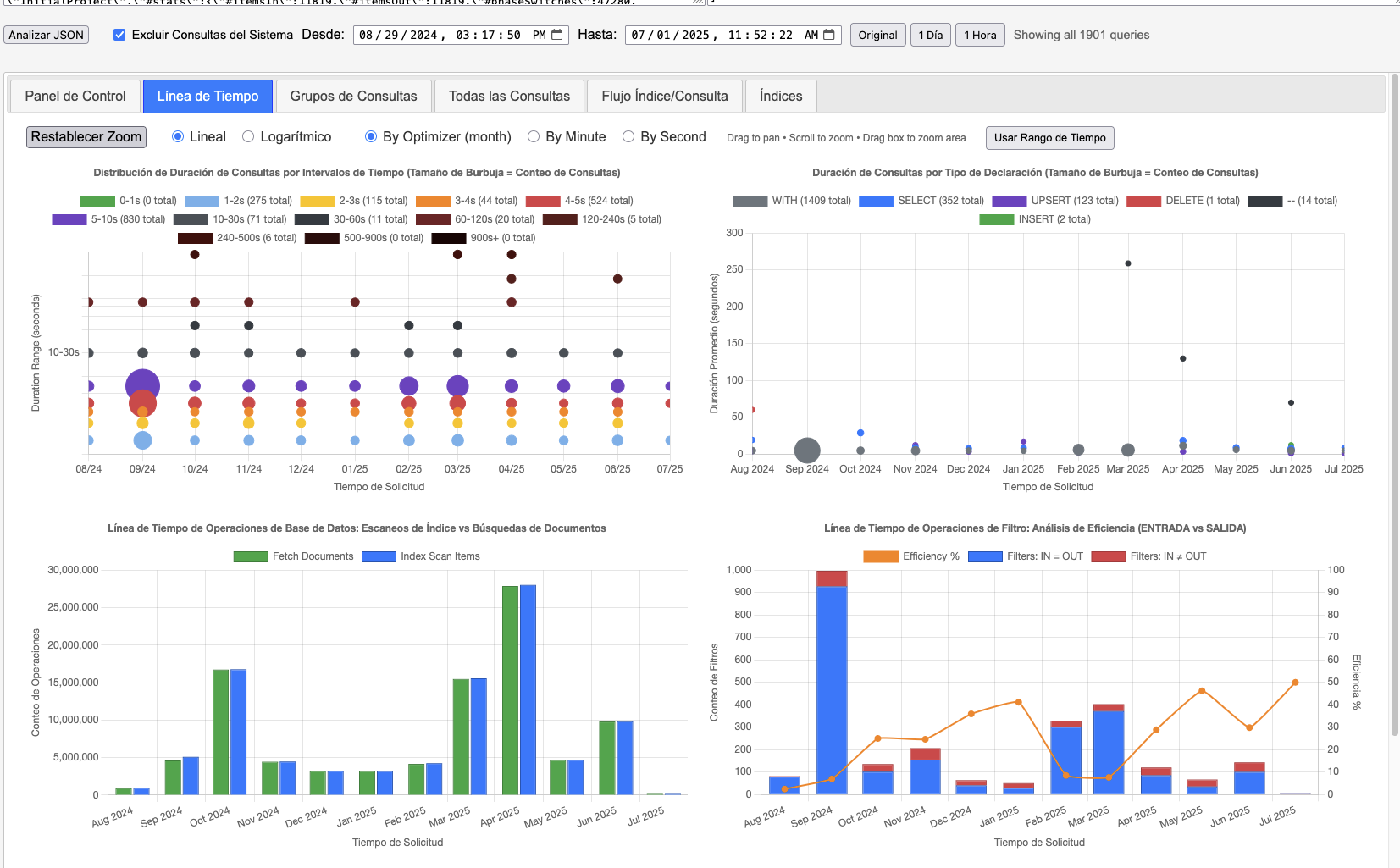
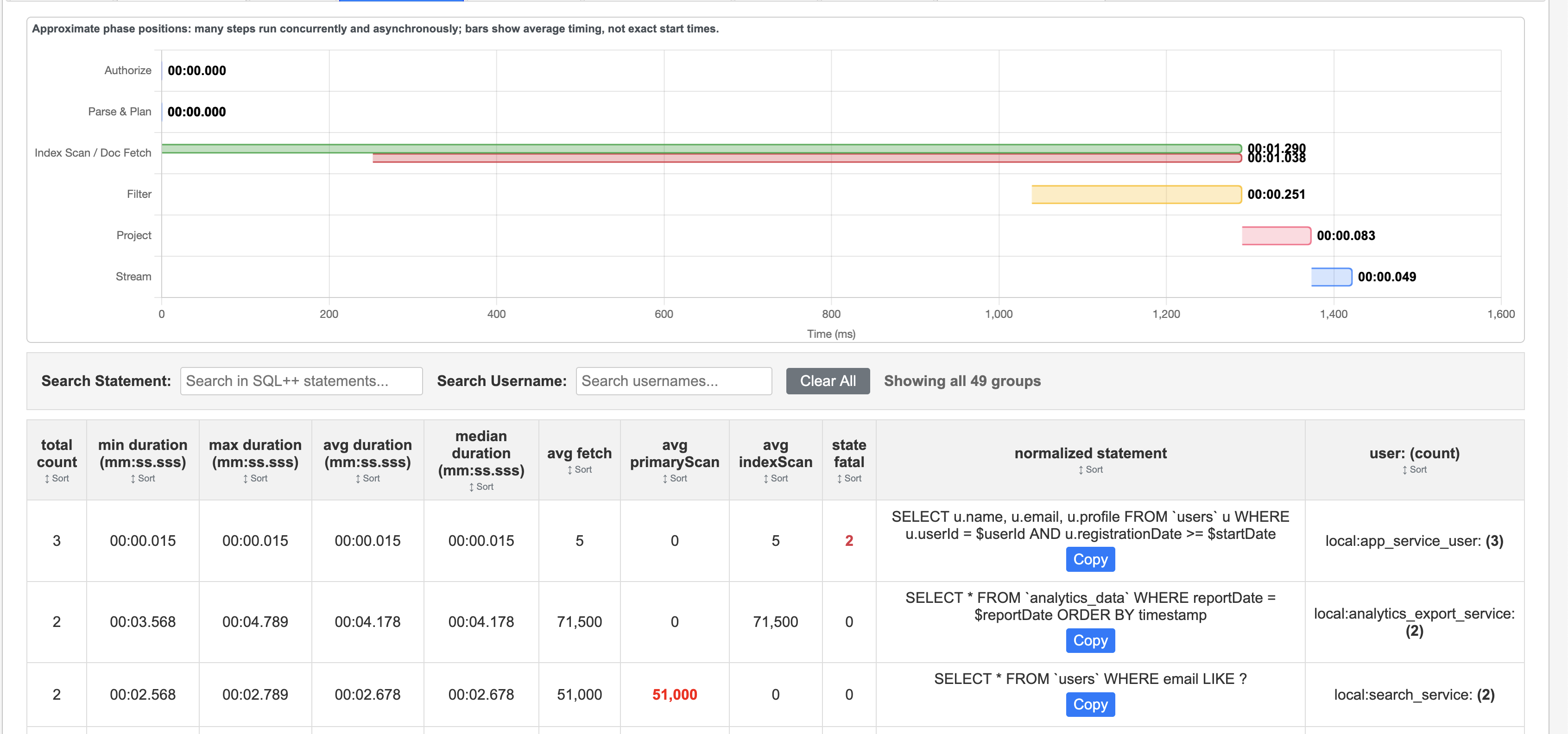
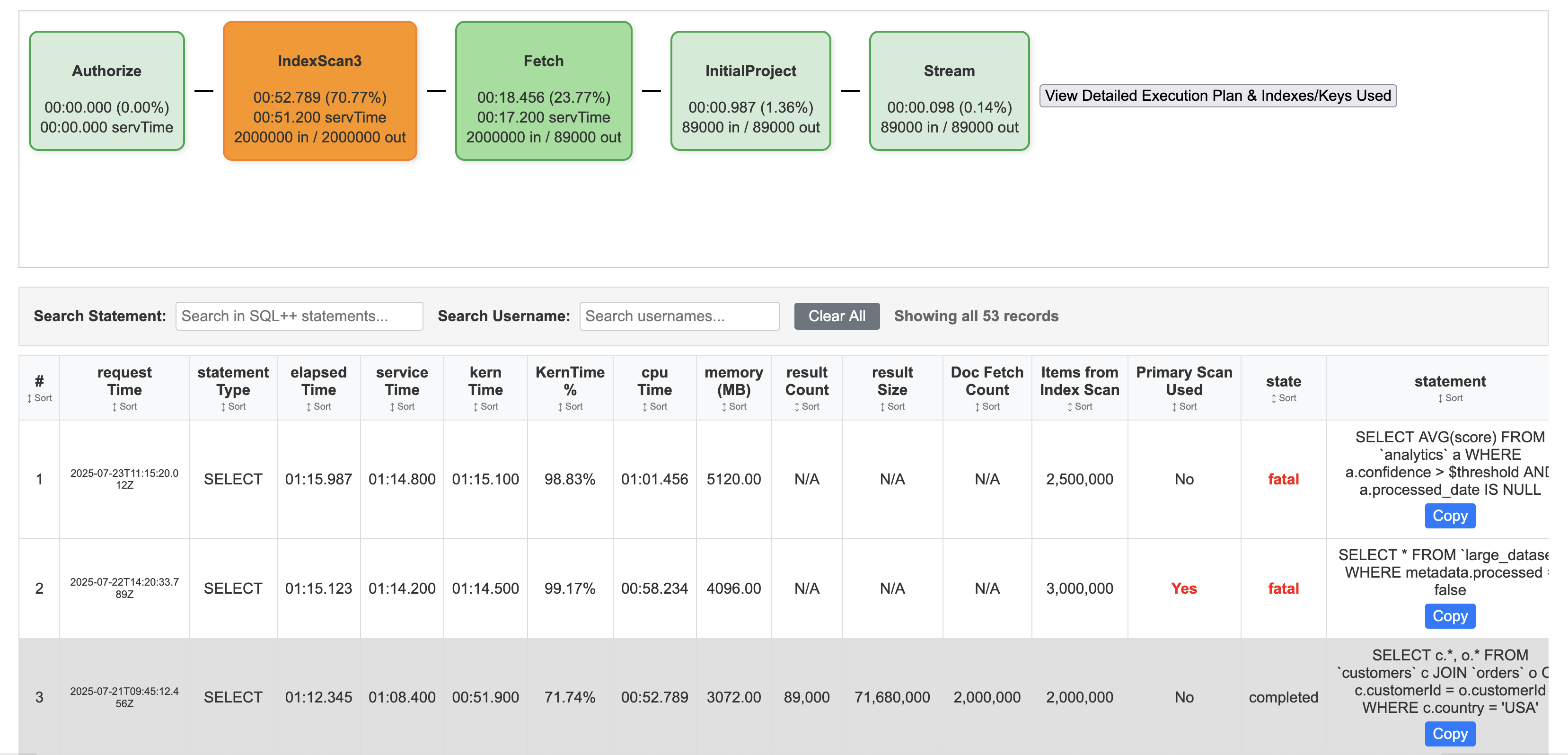
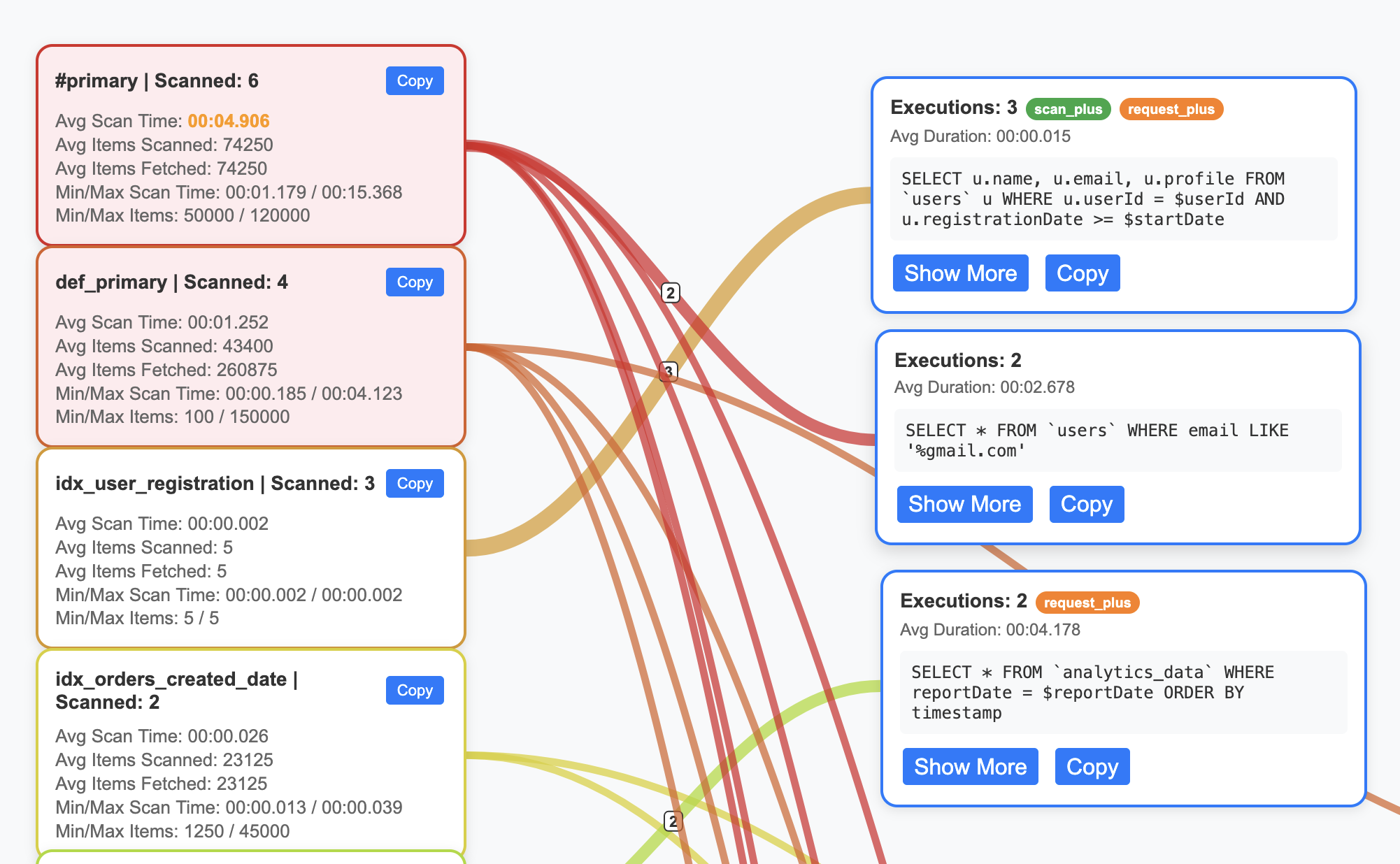
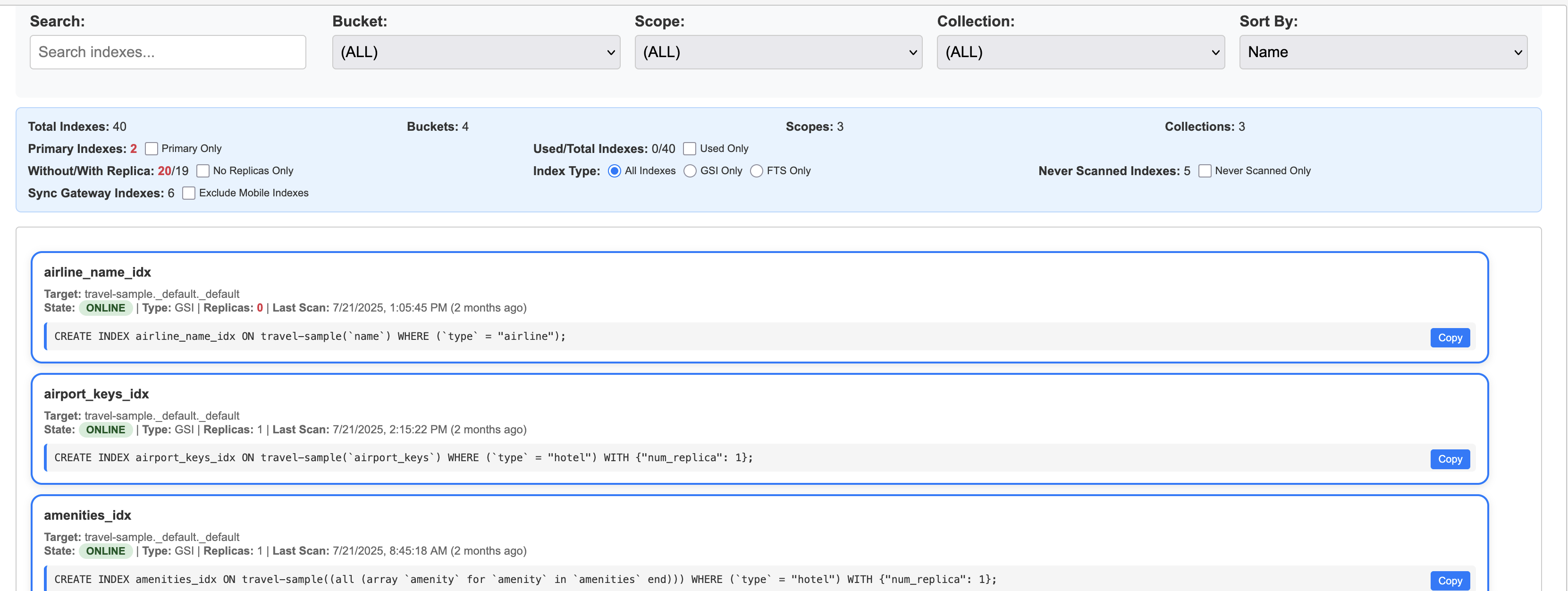
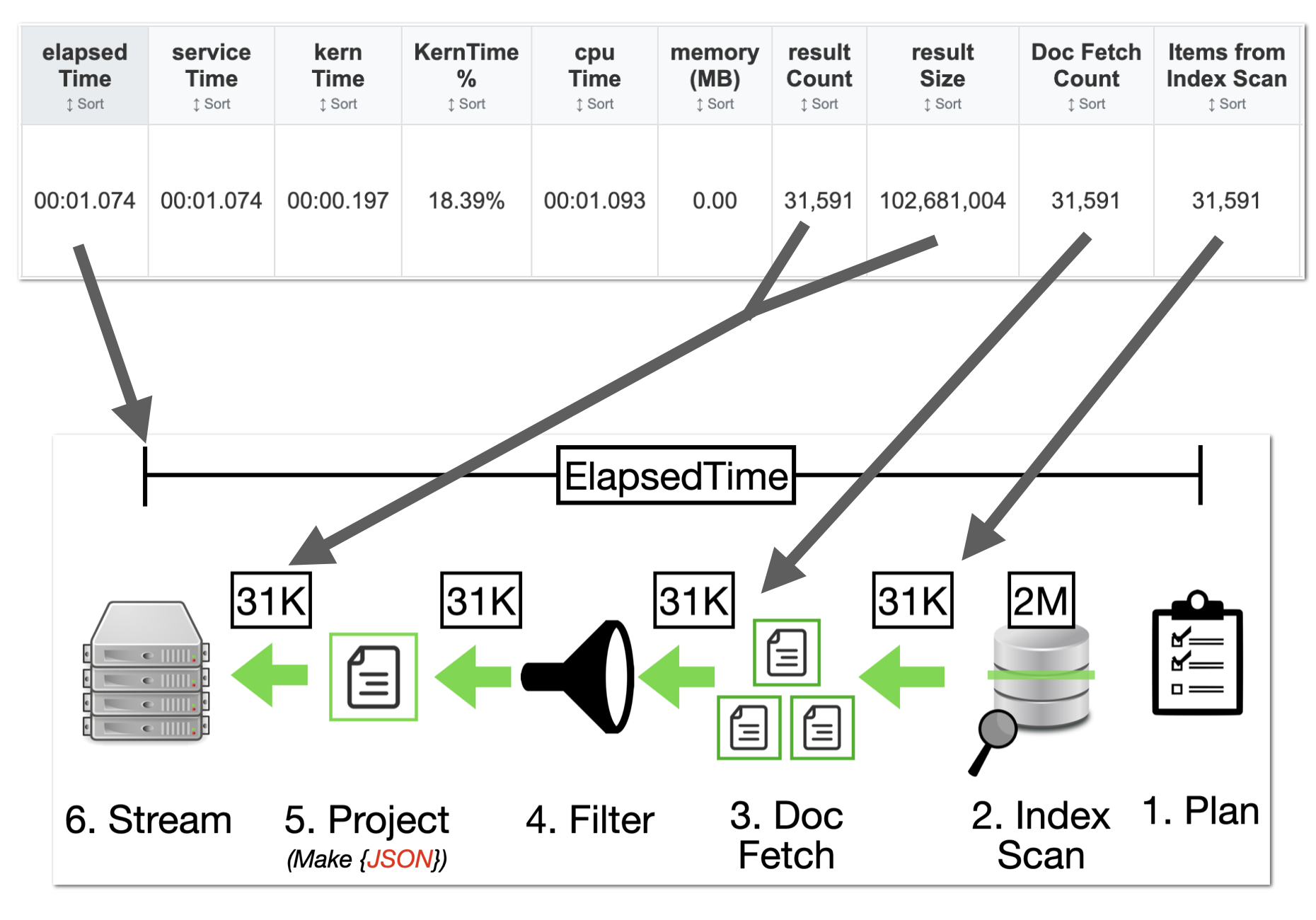
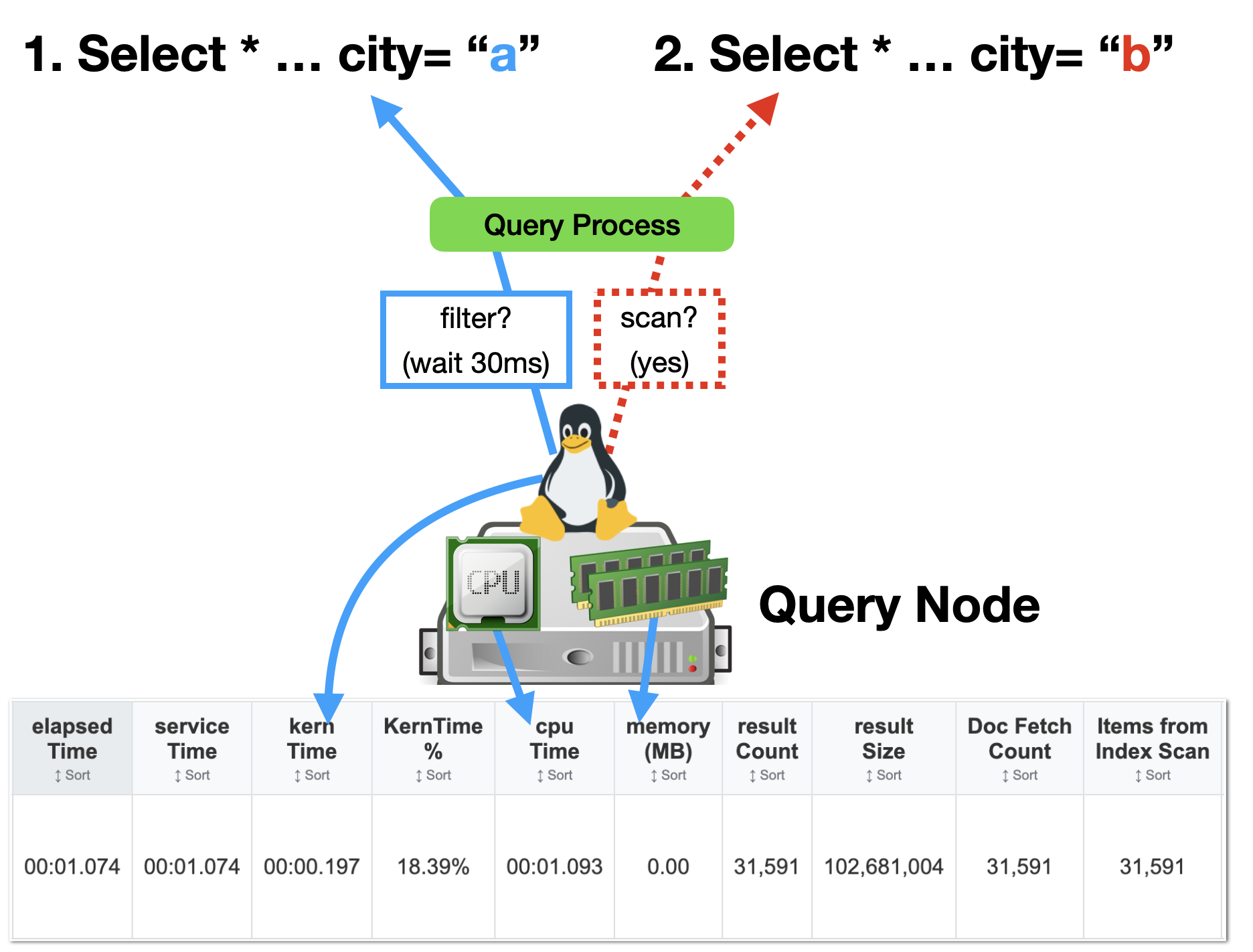
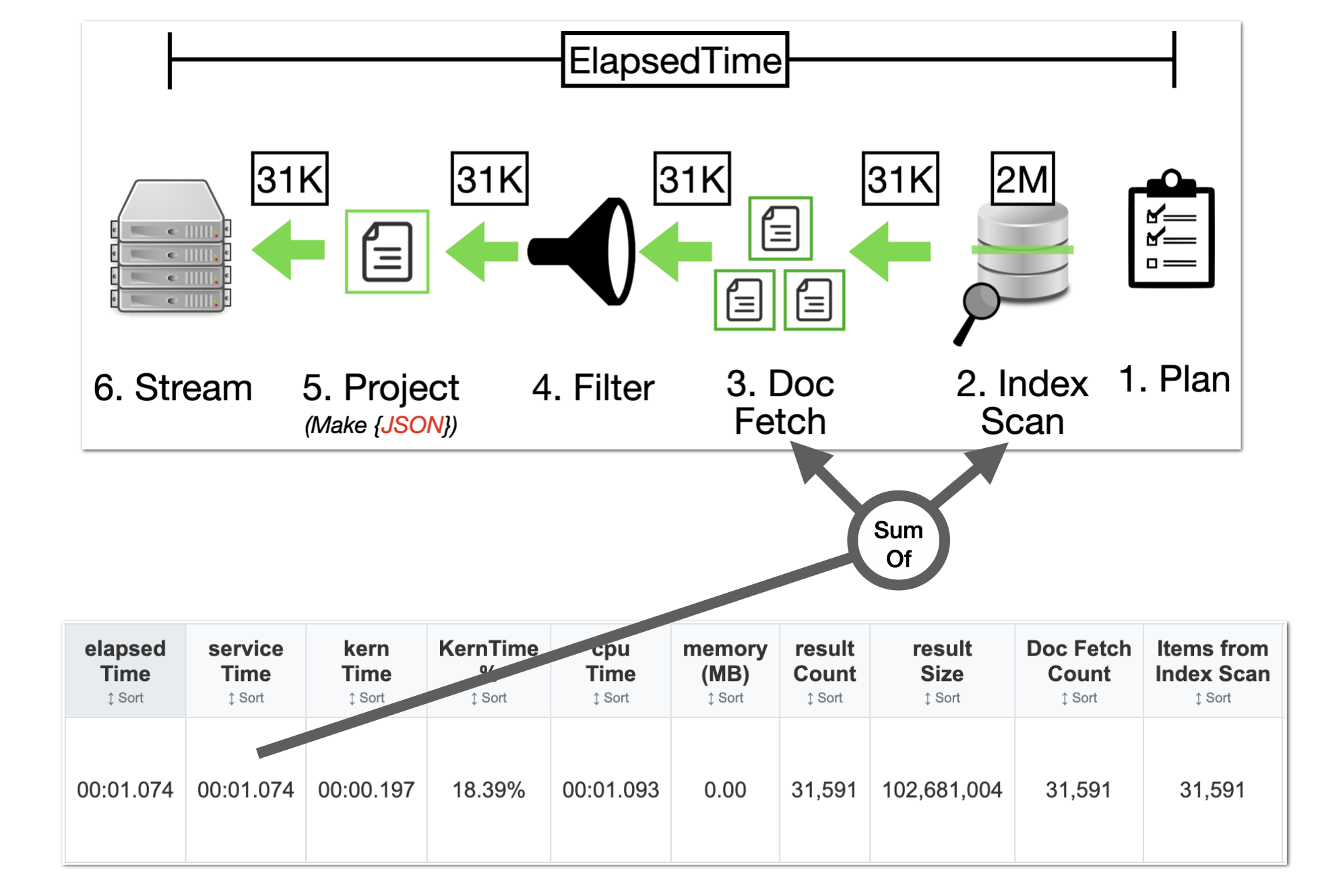
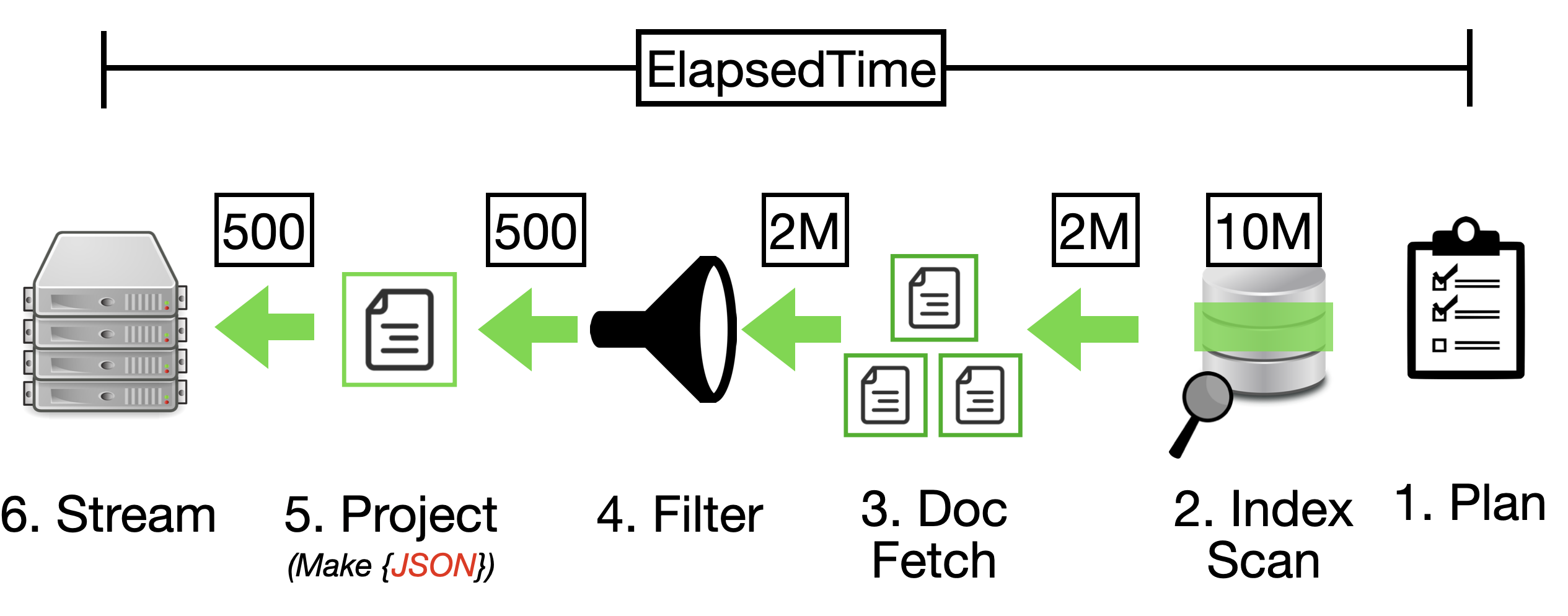
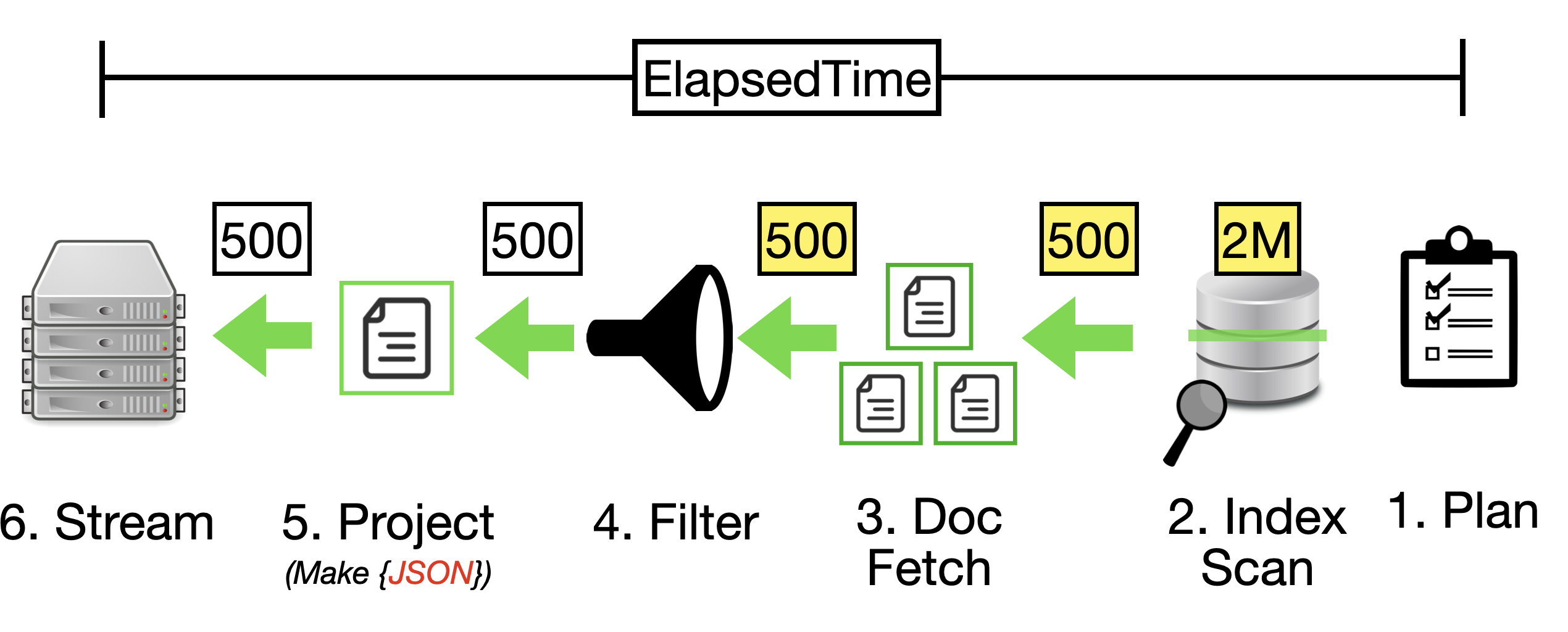
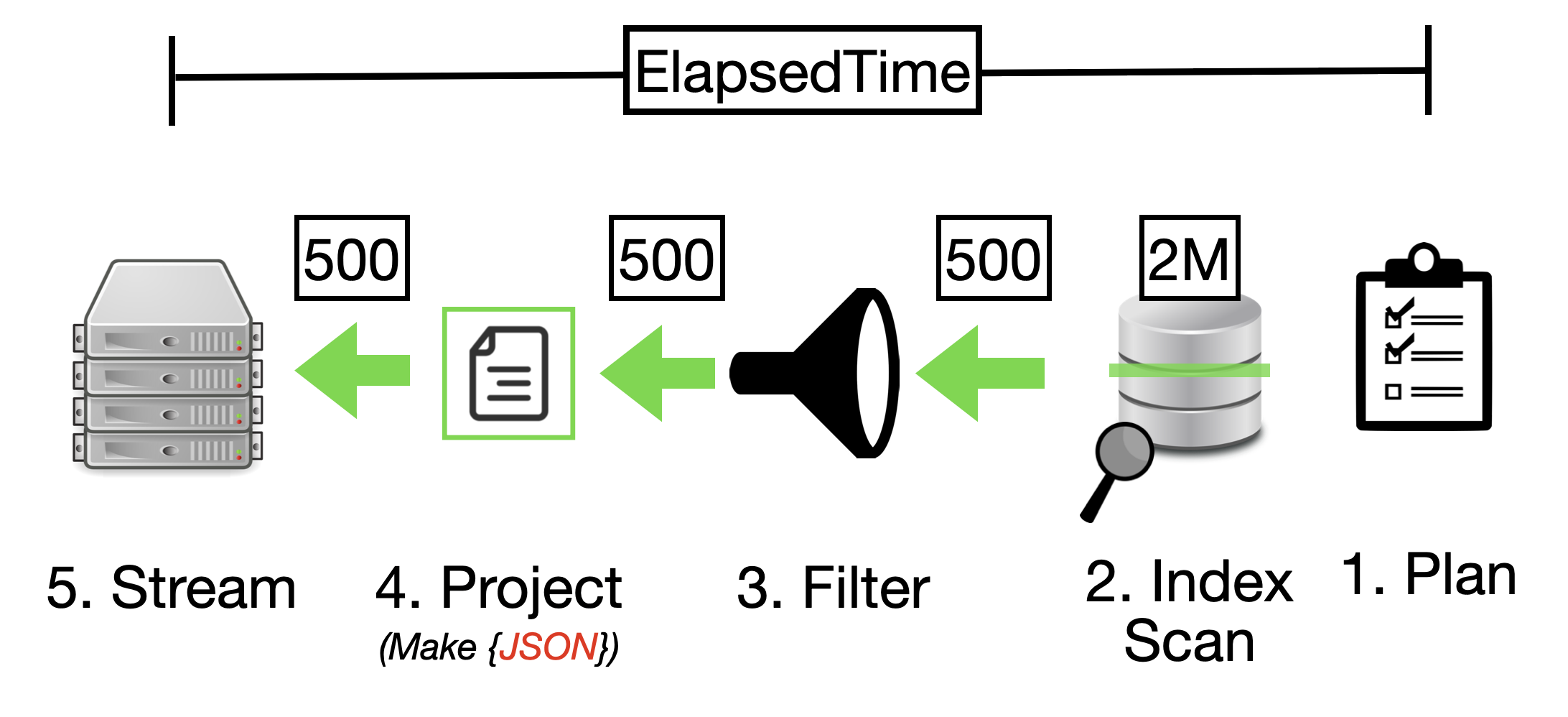
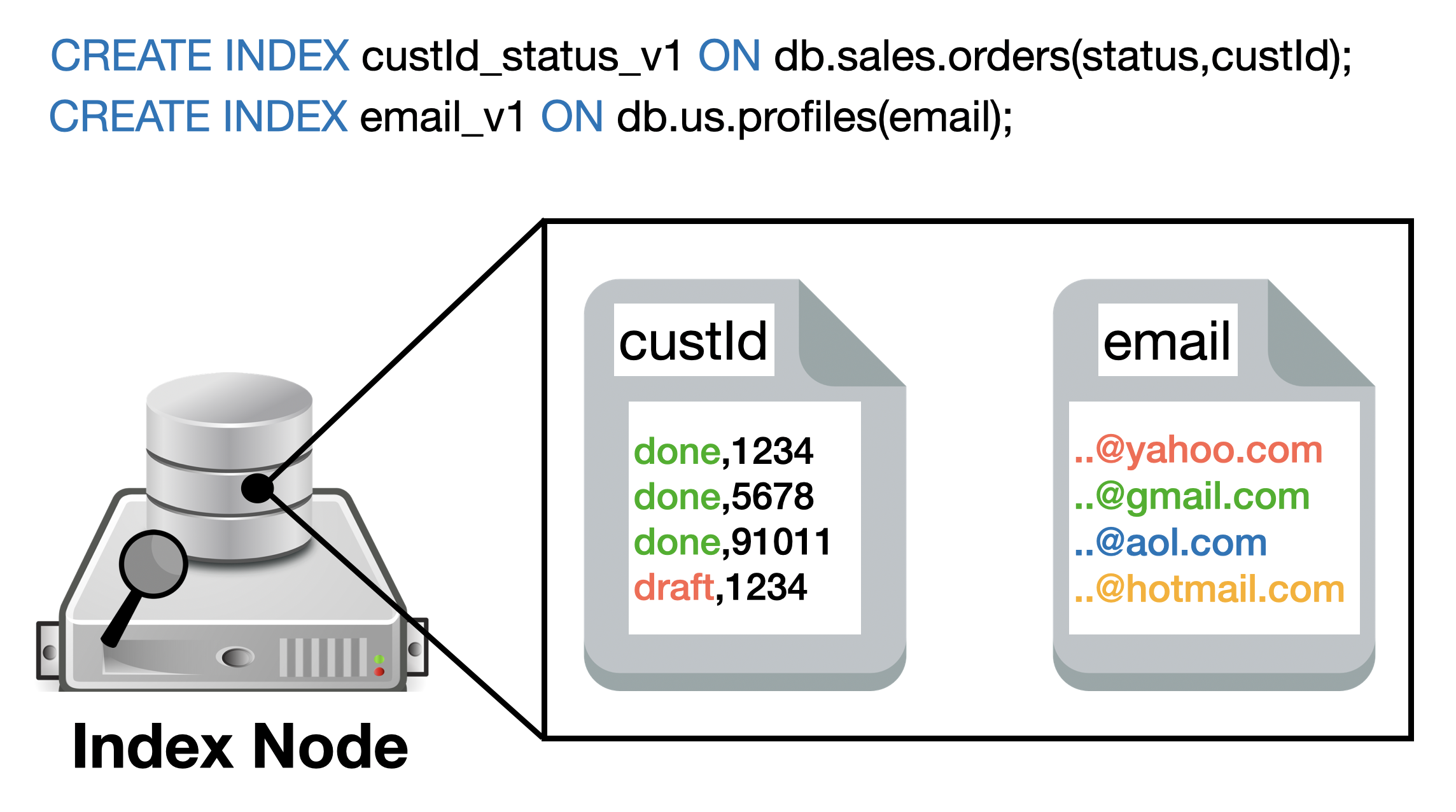
While primary indexes in Couchbase provide a basic way to scan all documents in a bucket by their keys, they come with significant drawbacks that make them unsuitable for most production scenarios. Primary indexes lead to very slow performance because they fetch all documents across all types in the bucket before applying filters, resulting in unnecessary I/O, memory, and CPU waste.
- Performance Impact: Excessive document retrievals and post-scan filtering make operations "VERY EXPENSIVE"
- Resource Waste: Unnecessary I/O, memory, and CPU consumption
- Not Recommended: The Couchbase index advisor never recommends primary indexes
- Better Alternatives: Secondary or composite indexes are almost always more efficient
Recommendation: Avoid primary indexes in production—use them only for initial data exploration or when no other index applies, and opt for targeted secondary indexes to minimize latency and resource usage.